我们先看一下什么叫事务?之前使用seata时的分布式事务也提到事务的概念,那是在微服务下的应用,那事务本身的概念是什么?
事务指的是访问或者更新数据库的一个执行单元,必须满足ACID特性的一组操作,要么全部提交完成,那么全部回滚恢复到没有数据之前,我们来看一下ACID是什么?
A(Atomicity):原子性,事务作为最小的操作单元,要么全部成功,要么全部失败
C(Consistency):一致性,在一个事务过程中,都是从一个状态变成另一个状态,中间过程做的事情作为一个整体,结合原子性,数据库都是一致的,要么全成功要么全失败
I(Isolation):隔离性,一个事务在提交之前,其他事务是不可见的,各个事务之间不能互相干扰
D(Durability):持久性,数据一旦提交就会永远保存在数据库中,事务的结果不会丢失,系统崩溃也可以通过备份恢复
总的来说:
事务是一个整体,要么都执行,要么都不执行,一刀切,数据入库落盘以后,结果永远不会丢失(delete一样,提交了这个事务,数据删了,那么数据就没了,这个结果不会变),隔离性是在并发的情况下需要满足,如果串行的话就没有隔离可言,因为都是单个事务处理,不需要讨论隔离性(好比负载均衡算法,但是如果只有一个节点,就没有均衡可言),当然大部分情况下我们都是并发的
并发一致性问题
刚刚提到的,在并发情况下要保证隔离性,就会有很多问题,我们罗列会产生的问题(下面抛开隔离级别来讨论的):
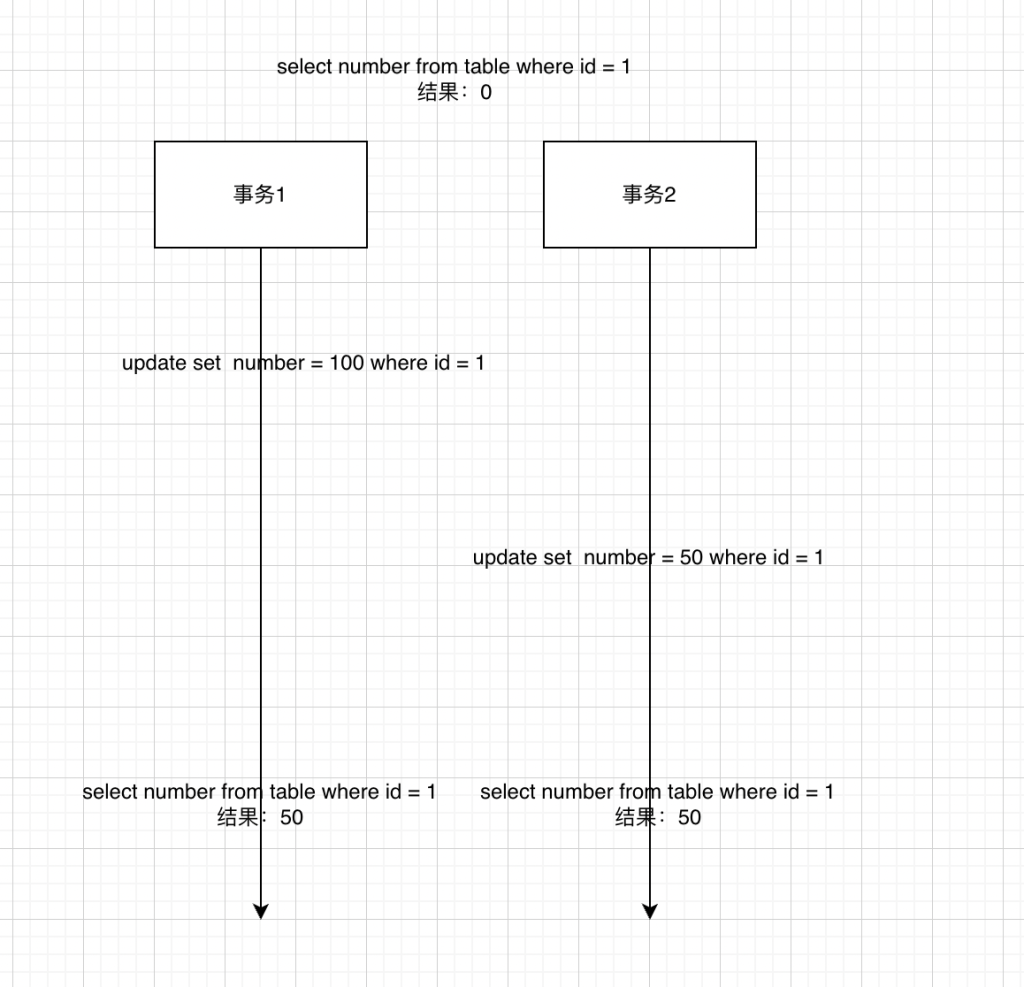
(1)修改丢失
说明:开启两个事务1、2,一开始id为的number = 0,此时事务1先update set = 100,然后事务2再update set = 50,最后两边查出来的结果是50,事务1很懵逼,修改了一个寂寞
(2)读脏数据
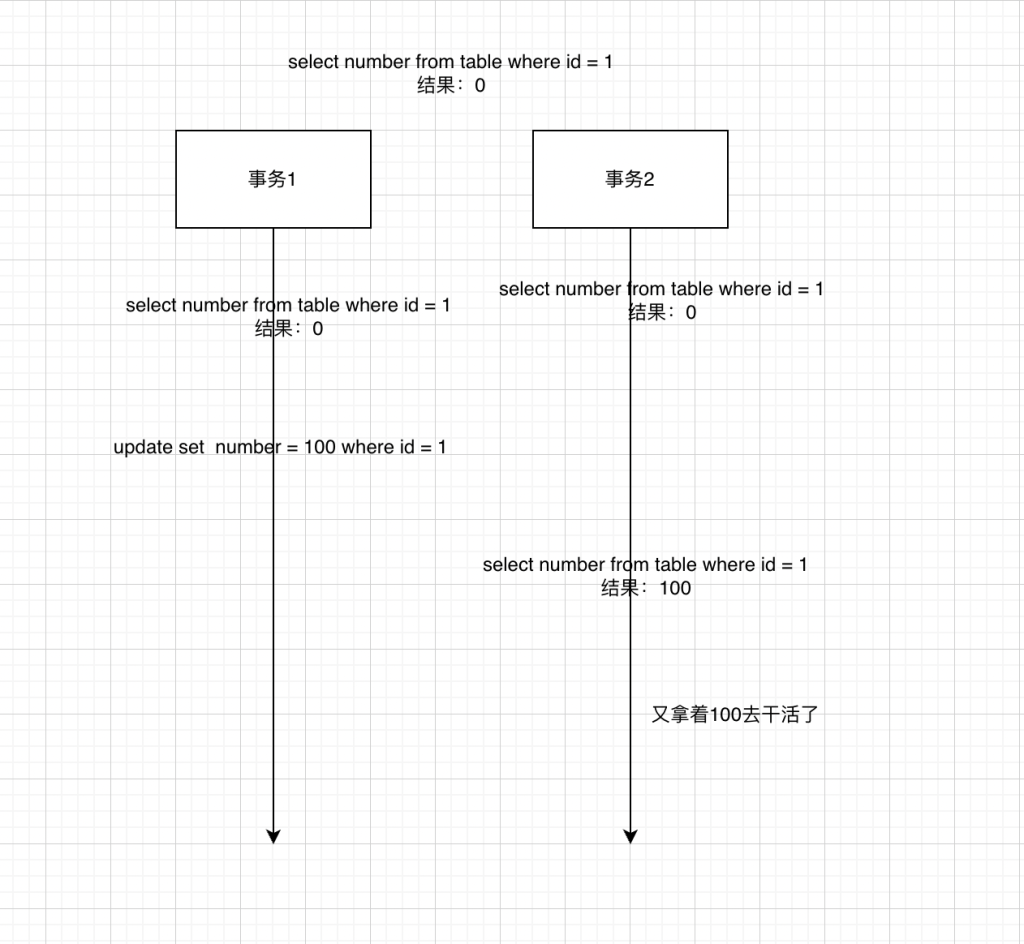
说明:同样事务1、2,原始数据是0,事务1开启,update set = 100,此时事务2查询到100,拿着100去返回数据或者做其他业务操作,然后事务1产生错误,回滚了,此时GG了,事务2拿的数据已经不存在了,这个数据是脏数据

(3)不可重复读
说明:开启两个事务,在事务1中,先查询了数据为0,然后改成100,在事务2中,在事务1修改数据之前查询,查询的数据同样是0,但是在事务1修改数据之后,业务需要再查询一次数据,结果查询是100,在同一个事务中,查询到的数据不相同,说明被其他事务给影响了,这种我们称为不可重复读(这个名称我一开始也蒙圈,为什么叫不可重复读,我理解为:在同一个事务中,没有修改数据的情况下应该拿到的数据是一样的,可以重复读取,称为可重复读,那反之,则为不可重复读)
(4)幻读
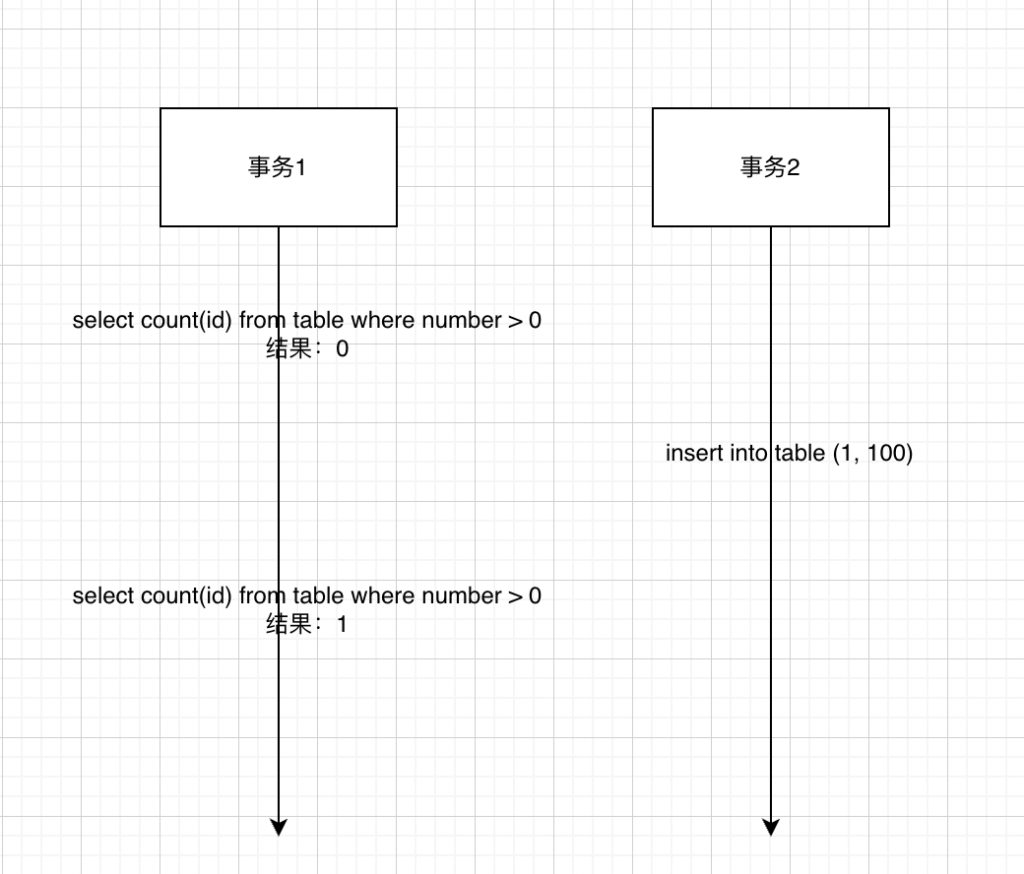
说明:这是最难理解的一种,跟不可重复读很像,但是一种特殊的情况;同样的两个事务,事务1聚合数据,查看number大于0的数据,第一次结果为0,事务2此时插入一条数据,然后事务1再次聚合数据的时候发现,结果变成1,产生了不一样的行数称为幻读(官方定义为一个事务中返回的数据结果不同则为幻读,是不是跟不可重复读很像,但区别就在于,幻读针对的是返回的条数,insert/delete都会影响条数,解决方式是利用间歇锁去解决,为啥是间歇的,就是因为返回的条数不同,所以只要我们锁定范围内的数据不就能解决这个幻读的问题了吗?但这里会存在其他问题)
针对上面的隔离性问题,MySQL设立了隔离级别,考量是性能和部分隔离性
(1)读未提交(Read Uncommitted RU)
(2)读已提交(Read Committed RC)
(3)可重复读(Repeatable Read RR)
(4)串行化(Serializable)
根据问题的严重性:脏读>不可重复读>幻读
根据隔离级别得到以下的情况:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| RU | 可能 | 可能 | 可能 |
| RC | 不可能 | 可能 | 可能 |
| RR | 不可能 | 不可能 | 可能 |
| Serializable | 不可能 | 不可能 | 不可能 |
RU性能高,但是青菜萝卜基本全部都可能发生,而串行化什么都能避免,但是性能最低,因此我们一般根据场景使用RR或者RC,数据库默认情况下是RR(像oracle,默认只支持RC跟串行化,我们当前只讨论mysql)
那么RR情况下,可能是存在幻读的,数据库又是用什么方式来解决幻读的,答案是使用间歇锁和next-key lock
间歇锁gap lock
我们回忆一下幻读出现情况,是被insert/delete影响了行数导致的幻读,所以就算你把整个表所有行锁住都没法解决数据插入问题,而间歇锁的目的就是把数据之间的间歇锁起来,防止在中间插入新数据
另:binlog的格式设置需要设置成row,不然会出现日志和数据不一致的情况,我们后续使用到cdc(capture data change)也是需要改这个设置的
next-key lock
行锁 + 间歇锁合成为next-key
我们后面专门再开一个篇章来学习锁,我们继续学习一下事务相关的,什么是MVCC,中文叫多版本并发控制,指的是数据在事务中的多个版本,并且为了在不加锁的情况下更好的处理读写冲突,非阻塞并发读
MVCC
这里有两个重要的概念,当前读,快照读
当前读:
读取当前记录的最新版本,读取时保证其他并发事务不能修改当前记录,会对读取的记录进行加锁,注:重点是最新版本,记住这个,实际上是加锁操作
如 select lock in share mode, select for update, update, insert, delete
快照读:
快照读是基于MVCC实现的,可以理解为行锁的变种,主要是为了避免加锁,之所以叫快照,如果学过其他关于这种命名的都知道,快照的数据是一组当前或者之前的数据,注:为了解决读写不冲突,并发读的一种解决方案,具体是有read view、undo log等去实现,我们继续往下学习
实现原理:每行记录除了我们的字段外,隐式定义了几个字段,trx_id、roll_ptr, row_id, 加上undo日志和read view共同完成
隐式字段:
row_id:隐含的主键id,如果没有主键,InnoDB会默认生成一个聚簇索引
trx_id:单调递增的事务id,记录这条数据创建或者最后一次修改的事务id
roll_prt:回滚指针,指向上一个版本
deleted_bit:记录被更新或者删除并不代表真的删除,而是删除flag变了,这个很有意思,更新或者删除都是操作一下这个旧版本的值,并不是真正直接删掉,另外会有个purge线程去清理这些数据
undo log:
一般有三种,insert(记录id,回滚时删除id)、update(记录旧值,回滚时更新回去)、delete(记录整条记录,回滚时插回去表),实际情况中,最多的是update undo log,每次更新数据,就会产生一条新的undo log,回滚指针执行上一条(第一条为null),实际上就是链表,链头是最新的旧的记录,链尾是最旧的记录(也许不是,标记deleted_bit删除的旧数据会被purge清理)
Read View(读视图):
我们之前讨论过很多,生成事务的时候,其他事务会有影响(不可重复读、脏读),那么read view的目的就是生成一个可见的快照视图,不同的时机或者隔离性下划分事务的范围,判断一下版本链中的哪个版本是当前事务可见的,这么说很抽象,我们来看一下怎么实现的再回过来理解
read view有三个全局属性:
trx_list:未提交事务id列表
min_trx_id:trx_list列表中最小的事务id
creato_trx_id:生成该read view的事务的事务id
max_trx_id:read view视图生成时刻尚未分别的下一个事务id,也就是当前已经出现的事务id最大的值+1(因为是并发环境,所以不一定是当前trx_list最大+1,是已出现事务最大值+1)
当前事务id trx_id等于creato_trx_id,对事务则可见,如果小于min_trx_id,则当前事务能看到trx_id的记录,如果大于或者等于,则与max_trx_id判断大小,如果大于或者等于则当前事务不可见,如果小于,判断是否在trx_list中,如果在则说明并未提交,当前事务不可见,如果不在则说明已经提交了,当前事务能见到了,这么说很头疼,我们画个图
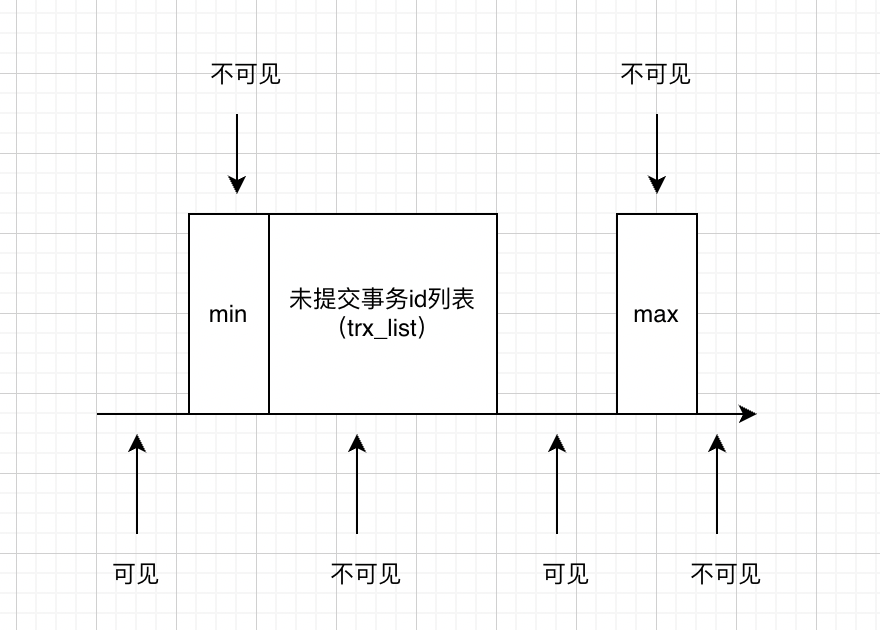
简单说明:
流程:select某一条数据数据,创建快照读(如果是当前读加for update,加行锁)
1、判断当前的事务id范围,如果是自己则当然是可见看到数据了
2、如果小于min(即在上图左边区间),则该事务已经提交了,该版本可以被当前事务访问
3、如果大于max(即上图右边区间),该事务是生成read view后开启的,所以这个版本没法被该事务访问
4、如果等于min、max或者在未提交的事务列表里,说明生成的read view时,这个事务还是活跃,那么不能当前事务访问
5、最后一个剩余的区间(max是最大事务+1,不一定在未提交事务中),说明创建read view时该事务已经提交了,可以被当前事务访问
那么在这里,RR和RC产生快照读区别就出来了,RR同一个事务中,第一个快照读才会创建read view,之后读快照都是同一个read view,而RC每次读个快照读都会生成并获取最新的read view