官方定义:Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments perform computations at in-memory speed and at any scale.
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
它有什么特点呢?
1、事件驱动(event)
2、基于流式处理,分为有界流和无界流
(1)无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
(2)有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
3、支持事件事件和处理时间语义,保证精准计算的同事,保证了事件的时序性
4、提供精准一次的状态保存,保存结果的同时,降低计算过程的资源消耗,同时保证异常终止后能断点恢复,保证数据在处理过程中的一致性
5、可以结合云原生kubernetes、Yarn等做资源调度,动态扩容,支持高可用
6、时间窗口操作,提供四种时间窗口来满足不同触发时机的需求
3、分层API
(1)越顶层的越抽象,使用方便,简明,但使用不够灵活
(2)越底层越具体,很利用,可以引入各种组件和库,但使用繁琐
相信大家在使用的大数据组件中,一定听过Spark,和Spark Streaming(基于流处理),Flink和Spark Streaming有什么区别?
(1)Spark Streaming使用RDD模型,Dstream实际上是由很小批的数据RDD集合,本质上还是批处理,而Flink采用数据流模型,基于事件序列
(2)Spark是批计算,将DAG(有向无环图)划分成不同的stage后,完成一个再进行下一个,而Flink则是基于事件,事件处理完则直接到下一个节点
Flink的部署
(1)Strandalone模式,单点模式,JobManager和TaskManager都在同一个节点上,一般用于测试
(2)Cluster模式,集群模式,JobManager和TaskManager分开,任务分发和执行分明,伪集群模式,一般可以用在小任务或者初使用,但不建议到生产
(3)Yarn,在yarn上运行,1.11之前的版本提供session-cluster和per-job-cluster模式,1.11以后提供session-cluster和application-cluster模式:1)session模式:启动一个集群并保持会话,所有作业都提交上来,作业结束了只会释放资源,适合小作业,执行完就释放的任务,缺点是JobManager的资源共享,如果JobManager资源不够的情况下,提交的作业会失败,并且同一个TaskManager上如果运行太多作业,宕机的情况下所有作业都会受到影响;2)application模式:启动一个集群,JobManager只为一个应用存在,如果关闭,集群也会释放资源,不同于1.11之前的per-job,per-job是单作业的模式,由作业对应集群,而application则是JobManager执行,也可以多个作业,相比per-job更灵活
(4)Kubernetes,交由云原生k8s部署运行,跟Yarn相类似,担任相同的角色,同样分为session、per-job和application模式,特点和Yarn下运行相类似,也是未来一站式的解决方案
(5)另,在Yarn可使用HA模式,需要依赖外部的Zookeeper复制组(quarum),Kubernetes HA需要运行在Kubernetes上,这种HA模式指的是多个JobManager,一个JobManager担任lead,如果挂了其他备用的JobManager来接管,我理解为类同hdfs 的NameNode HA和Yarn的ResourceManager HA
Flink运行架构
以上讲了一些部署方式,上面提及到JobManager和TaskManager的概念,下面讲一下具体运行时会涉及到的组件
(1)JobManager 控制应用执行的主进程,它负责把作业变成JobGraph,再转成一个物理层面的数据流图,并向ResourceManager请求资源
(2)ResourceManager 负责管理TaskManager的slot,TaskManager的slot相当于资源单元,作业吊起时候JobManager得出需要的资源后向ResourceManager申请资源,根据不同的模式,再调起TaskManager进程来满足JobManager的请求,另,还负责终止空闲的TaskManager,释放资源
(3)TaskManager 作业会在TaskManager中运行,每个TaskManager都包含了slot,这个由CPU和作业发起者去设置,slot会限制TaskManager能够执行的任务数量,另外可和其他的TaskManager进行数据交换,一般会有数据广播等方式,内存模型中有一个网络通信的内存分配就是为了满足这块,通信的目的是为了满足更大并发和计算量的作业,当然需要结合一定的场景和一些调度策略来满足
(4)Dispatcher 当应用被提交执行时,Dispatcher将应用移交给Jobmanager,对外提供REST接口,是一个集群的HTTP接入点,我感觉有点像是对外API的出入口,它还会启动一个Web UI,就是我们常用看作业情况的Web界面,监控、展示作业执行的信息,可以在上面查看通信情况、背压、内存使用率、日志等等
作业提交流程图
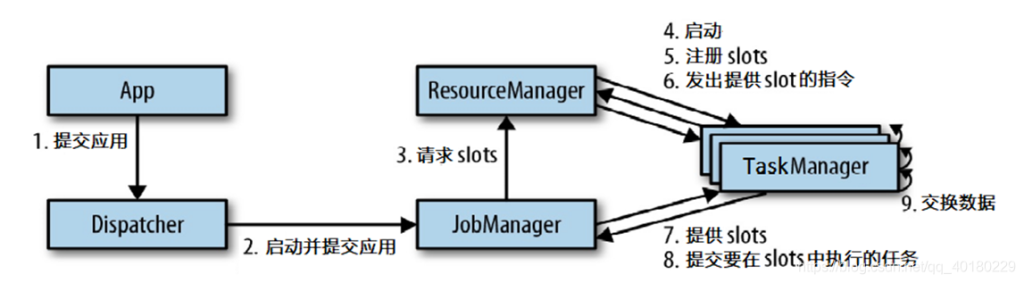
目前我搭建的是使用Ambari管理的Yarn集群,整个提交流程如下:
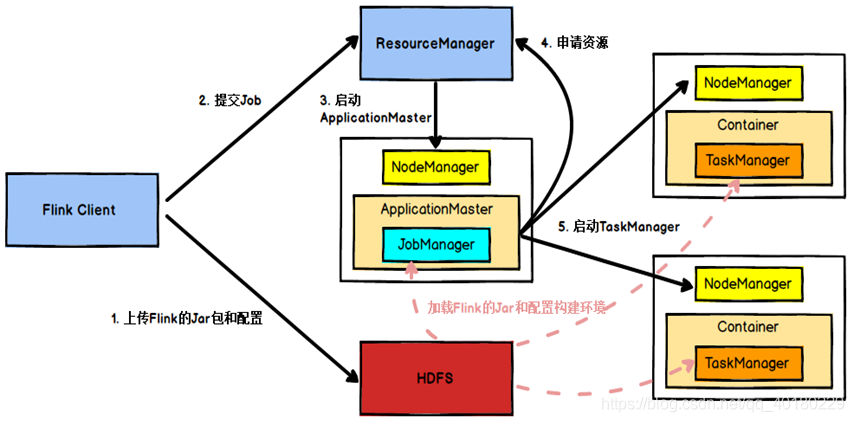
- Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
- 之后客户端向Yarn ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster
- ApplicationMaster启动后加载Flink的Jar包和配置构建环境,去启动JobManager,之后JobManager向Flink自身的RM进行申请资源,自身的RM向Yarn 的ResourceManager申请资源(因为是yarn模式,所有资源归yarn RM管理)启动TaskManager
- Yarn ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
总结:
简单介绍了Flink的特点、运行结构和运行架构,Flink是当下低延时、具有精准一次语义和基于事件时间的流式处理引擎,而且很好的适配当下主流的Yarn、kubernetes,是未来大数据云计算的主流框架,目前社区正在快速迭代,支持数据量更大、更多的场景,另外还有CDC这些优秀的组件和丰富的资源库填补完整应用,后续还会介绍Flink SQL等的实战应用