1、Client将代码编译后,将来Dataflow graph提交作业给JobManager后则是一个独立的部分,不会运行在Yarn中,它直接可以断开,也可以和Jobmanager保持通信,获得状态更新和统计的结果,像我们用到的zeppelin/streamx/dinky等
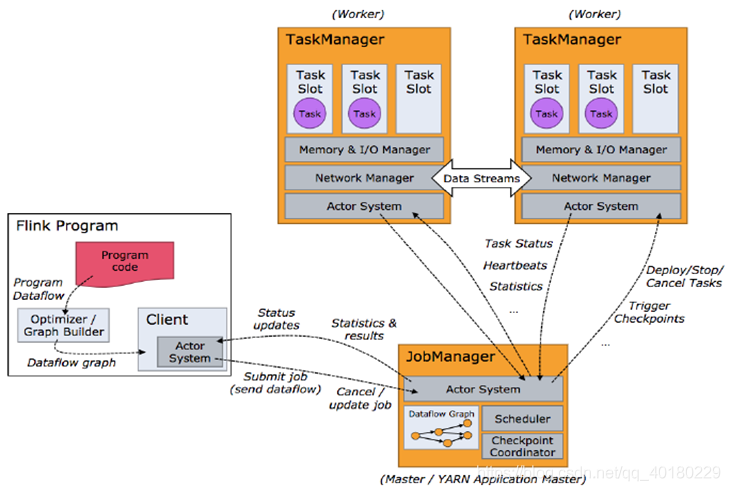
2、flink集群启动后,会先启动一个JobManager,根据不同模式,会在不同的契机启动一个或者多个TaskManager, JobManager会把任务调度到TaskManager中执行,JobManager和TaskManager有着不同的JVM模型规划,不同模块会负责不同的任务,如下图所示,TaskManager会和JobManager保持心跳通信和统计信息的同步,如果TaskManager之间需要进行数据传输,则以流的形式进行数据传输,在内存模型中的Network Manager去管理
3、JobManager主要负责调度Job并协调Task做checkpoint
4、TaskManager启动时会根据设置的slot进行资源计算,执行对应的算子,在一些情况下如果slot不能满足会停止任务
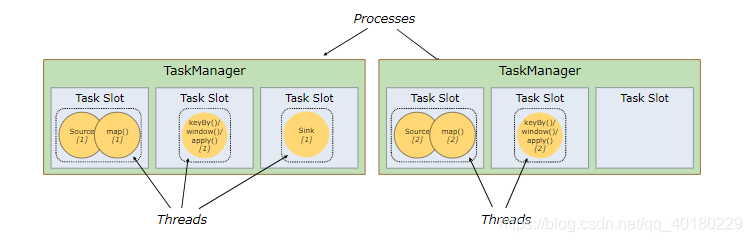
我们暂开聊一聊TaskManager和slot
实际上,运行的Job需要的Slot = 每个组Slot组中最大并行度
举个例子:我们可能会有一个Job,里面会有很多算子,比如source、window、map、sink等等,那么一个算子就会需要对应的slot,此处我们会对不同算子进行了一个分组,假设以上的四个算子所需要的slot为:source(1)、window(1)、map(2)、sink(1),我们的任务是source(获取数据源)→window(开窗)→map + sink(处理数据并下沉)那么此处我们分成了三组,那么所需的slot = math.max(1) + math.max(1) + math.max(2, 1) = 1 + 1 + 2 = 4 如图所示:
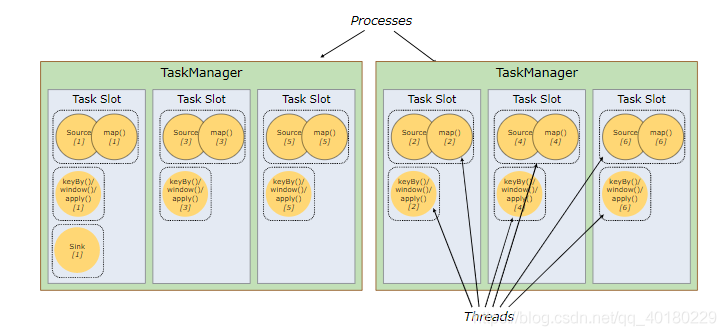
那么,理解了这个情况下,Flink的设计是运行子任务共享slot,所以一个slot也可以执行整个管道的作业,这样的好处是:(1)省去通信的问题,从source来,直接window后map下沉,(2)如果某个slot出现了异常,那么其他的slot可以补上,提高了整体执行的健壮性,(3)共享的好处是避免不同的slot执行的任务不平均,出现数据倾斜,或者资源分配不均的情况,当然也有坏处:所有的任务都放在一个slot里了那么资源就是共享的,如果出现资源竞争,则就不能并行了
如下图所示:
上面有提到并行,其实Flink的参数中是有一个并行度的概念,有两个参数,一个是numberOfTaskSlots,另一个是parallelism,那么这两个有什么关系呢
首先,slot体现TaskManager的并发执行能力,而parallelism则是提现TaskManager实际的使用并发能力,什么意思呢?
slot是用来隔离task的内存,不会涉及到cpu的隔离,如果一个TaskManager有一个slot,那么每个task group运行在独立的JVM中,如果有个多个solt则意味着更多的subTask共享同一个JVM,同一个JVM中的task将共享TCP连接、心跳信息等,同样的也会可以共享数据集、数据结构,减少每个task的负载。
而parallelism又称为并行度,是每个子任务subtask的个数,可以认为是所有算子的最大并行度,在设置slot时,所有设置的最大并行度大小则就是所需设置的slot数量
举个例子:如果有三个TaskManager,每个TaskManager中分配3个slot,那么也就是每个TaskManager可以接收三个task,一个有九个slot,那么如果我们设置并行度为1的情况下,那么9个slot只用了1个
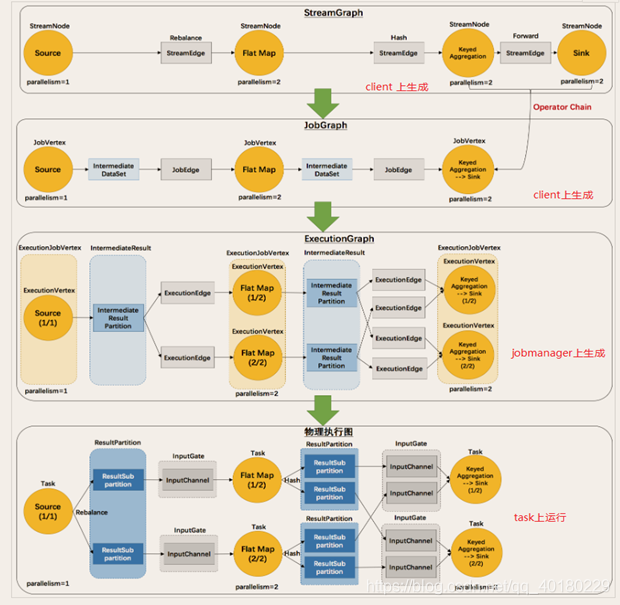
执行图
Flink会把执行的程序变成数据流图,我们称为执行图可能比较好理解一点
执行图有四层:StreamGraph→JobGraph→ExecutionGraph→物理执行图
StreamGraph:程序或者代码生成最初的图
JobGraph:交给JobManager的数据结构,是由于StreamGraph经过优化之后的生成的,将多个符合条件的节点合并,减少数据流动之间的序列化/反序列化/传输消耗
ExecutionGraph:根据JobGraph生成的ExecutionGraph是并行化的,是调度层最核心的数据结构
物理执行图:在TaskManager最后行成的图,并不是一个数据结构
算子之间传输的形式有两个模式:
One-to-one:最简单也是这种,所有的算子生成的元素个数、顺序都是相同的,转换过程都是一对一对应关系,也是比较容易维护的
Redistributing:当分区会发生改变时,不同的算子的子任务需要转化再发送到不同目标任务时就会使用到这种方式,也就是我们常听说的重分区,有broadcast和rebalance会随机重新分区,而keyBy进行hashCode重分区则到对应hash的分区上,这个过程就叫redistribute,在spark中这个过程叫shuffle,在kafka叫reparation,过程相类似。