数据库是如何工作的?
数据库内部核心组件:
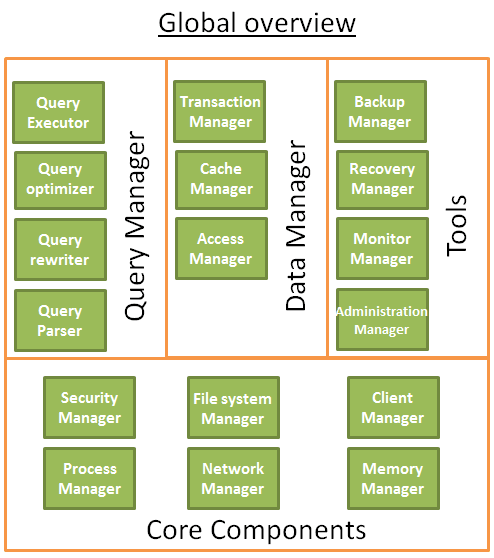
进程管理器:管理进程和线程池
网络管理器:管理网络IO
文件系统管理器:管理和处理磁盘IO
内存管理器:对内存进行管理
安全管理器:对用户的鉴权、校验等
工具:备份管理器(保存和回复数据)、恢复管理器(用于崩溃后重启)、监控管理器(记录数据库活动信息和提供监控数据库)、管理员管理器(保存元数据和提供数据库、模式、表空间的工具)
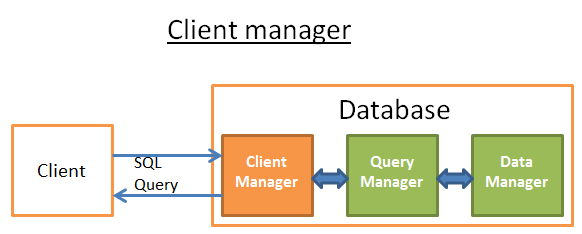
客户端管理器:用于管理和客户端的连接
查询管理器:由查询解析器(检查查询是否合法)、查询重写器(预优化查询)、查询优化器(优化查询)、查询执行器(编译和执行)组成
数据管理器:由事务管理器(处理事务)、缓存管理器(管理数据缓存读写操作)、数据访问管理器(访问磁盘中的数据)
查询的整个大致工作过程:
客户端请求查询→解析并判断是否合法→预优化,重写一部分操作→优化查询性能,索引等,并转换成可执行代码和访问计划→编译、执行
这些过程大致由以下的组件完成:
查询解析器:检查表是否存在、字段是否存在、函数是否合法
查询重写器:预查询优化,去掉一些不必要的运算(如子查询优化、去掉一些重复函数)
查询优化器:基于成本优化,通过应用成本最低的方式来找到最佳查询方案,cpu、磁盘、内存等,大多数的瓶颈是磁盘IO而不是CPU。优化器还会对索引进行成本运算,唯一查询、范围、联表(嵌套、合并)、排序等,因为需要在优先的时间找到一个解决方案,所以会结合算法,比如动态规划、贪心等,最后保存执行计划(保存计划还有缓存的设计)
查询执行器:将优化好的执行计划编译成可执行的代码
整个查询工作流程大概如上,变成成可执行代码以后,会与数据管理器进行交互,数据管理器中同样有几个组件组成
缓存管理器:提供一个内存缓存区,又叫缓存池,从内存中取数据能显著提高性能(当然这是一个耗内存的方案),一般会采取LRU算法(最近最少使用)
事务管理器:保证事务具有ACID特性
A:原子性,要么全部完成,要么全部取消
C:一致性,只有合法的数据能写入数据库
I:隔离性,A、B事务同时运行,最终结果是相同的,这样是保证一致性
D:持久性,一旦事务提交,不管失败还是出错,都会保存在数据库中
锁管理器:为了保证事务特性,一般会有个锁去解决对数据操作操作的并发问题(增改删)
悲观锁/排它锁:只有一个事务能操作这条数据,其他的只能等这个事务释放
共享锁:读数据的时候上共享锁,写的时候上排它锁,但是需要等待所有的共享锁都释放之后才能上锁,当上了排它锁以后,如果想读数据则只能等待锁释放
死锁:两个事务互相等待,形成死循环
其他:意向锁、行锁、表锁等,颗粒度不同,作用不同,但是思路是相同的,后面专门讨论,本篇主要是认识数据库的工作原理
日志管理器:因为我们把数据都保存在内存缓冲区里,一旦服务崩溃了,内存会随即销毁,没有提交的事务或者数据就莫得了,这就破坏了事务的持久性,因此有了事务日志的概念,使用预写日志协议来处理事务日志,这里很复杂,除了规则以外,为了提高写日志的性能,同时还引入了日志缓冲区,配合策略可以做到崩溃后能恢复数据库,其中还包括了存档点(checkpoint)的概念,这里不深究,我们来看一下一条事务日志有什么?
日志序号LSN、事务idTransId、数据的位置PageId、日志链路PrevLSN、取消操作的方法UNDO(类似于before)、重复操作的方法REDO(类似于after),后续配合MVCC的原理我们再来研究一下
总结:
数据库核心组件分别有着不同职责,在我们进行数据库查询时,需要用到查询管理器对查询进行解析、重写、优化并编译执行,执行过程会跟数据管理器进行交互,并且为了实现事务的ACID特性,由事务管理器、锁管理器和日志管理器共同完成。