Redis是内存高速缓存数据库(NoSQL),是基于kv存储系统设计,用C语言编写
Redis读写性能优异,数据类型丰富,且所有操作有原子性,还有持久化和订阅发布的功能
使用场景非常:
(1)热点缓存:一些不需要在乎实时性的数据,同时降低对数据库的访问,但需要注意缓存击穿和穿透等问题
(2)限时业务:手机验证码倒计时,限时优惠活动,因为redis对键值有过期时间设置,可以利用这个特性
(3)计数器:利用原子性,实现秒杀、分布式序列号生成、接口限制用量等需求
(4)分布式锁:这个很有意思,比如在我们分布式系统中,两个定时任务同时触发了,我们只运行一个线程操作,可以让上锁成功的任务执行,另外的任务直接舍弃本次
(5)延时操作:类似于rabbimq和kafka等消息中间件,利用发布订阅的功能,为一个key设置时间,然后做一个过期的监听器,当触发过期的时触发监听器业务逻辑
(6)排行榜:可以利用SortedSet的特性进行热点数据的排序
(7)点赞、好友互相关注:利用redis的一些集合命令,例如交集、并集、补集等,实现共同好友、关注人等功能,不一定是这类型,只要是能使用集合操作的场景都适用
(8)队列:提供简单的队列功能,同样类似于rabbitmq
基本数据类型:
(1)String:字符串
(2)List:链表,双向链表,可以push或pop
(3)Set:无序集合
(4)Hash:无序散列表
(5)Zset:有序映射的散列
(6)HyperLogLogs:基数统计,可以用作UV统计等场景,但是跟布隆过滤器类似,不一定准确
(7)Bitmap:位存储,位图数据结构,用二进制来记录,只有0和1,可以用作只有两个状态的场景,优势是存储成本非常小
(8)geospatial:地理位置
(9)geohash:使用比较少(反正我没用过),底层是Zset
(9)Stream:在5.0版本后新增的数据结构,命名是流,但实际上更像消息队列
在底层,redis是对象设计机制,对象结构redisObject
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型 4位
unsigned type:4;
// 编码方式 4位
unsigned encoding:4;
// LRU - 24位, 记录最末一次访问时间(相对于lru_clock); 或者 LFU(最少使用的数据:8位频率,16位访问时间)
unsigned lru:LRU_BITS; // LRU_BITS: 24
// 引用计数
int refcount;
// 指向底层数据结构实例
void *ptr;
} robj;type:
/*
* 对象类型
*/
#define OBJ_STRING 0 // 字符串
#define OBJ_LIST 1 // 列表
#define OBJ_SET 2 // 集合
#define OBJ_ZSET 3 // 有序集
#define OBJ_HASH 4 // 哈希表encoding
/*
* 对象编码
*/
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* 注意:版本2.6后不再使用. */
#define OBJ_ENCODING_LINKEDLIST 4 /* 注意:不再使用了,旧版本2.x中String的底层之一. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
看ptr,学过c的都知道,这样表示是一个指针,指向实际保存值的数据结构,这个结构由type和endcoding决定
lru记录了对象最后一次被命令程序访问的时间,当前时间减去lru时间则为空转时长,根据一些策略,如果这个值比较大的话有优先被服务器回收
底层数据结构
字符串:sds,用户数据用户会有一个\0,组成buf,一般有四种
sdshdr8/sdshdr16/sdshdr32/sdshdr64
分别由len|alloc|flags组成
len代表长度,buf[]数组存储每个元素,alloc分别以uint8|16|32|64表示整个SDS(除去头部和尾部的\0后剩余的字节数),flags以低3位标识头部类型,高5位未使用
| C语言字符串 | SDS |
| 获取字符串复杂度O(N) | 获取字符串复杂度O(1) |
| API不安全,造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度B次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本数据,也可以保存二进制数据 |
| 可以使用string.h库所有函数 | 可以使用string.h库中一部分函数 |
压缩列表,Ziplist,可以存储字符串、整数,存储整数是采用整数二进制而不是字符串形式存储,能在O(1)的时间复杂度完成list两端的push和pop操作
整个ziplist的内存存储格式如下:

zlbytes是整个ziplist所占用的内存字节
zltail是最后一个entry的偏移量,可以快速定位最后一个entry并完成pop等操作
zllen是整个ziplist中entry的数量,只占2bytes(16位),如果超过了65535(2的16次方),该字段值就固定式65535,实际的数量只能一个个遍历才能知道
zlend是一个终止符,其值为全F,即0xff
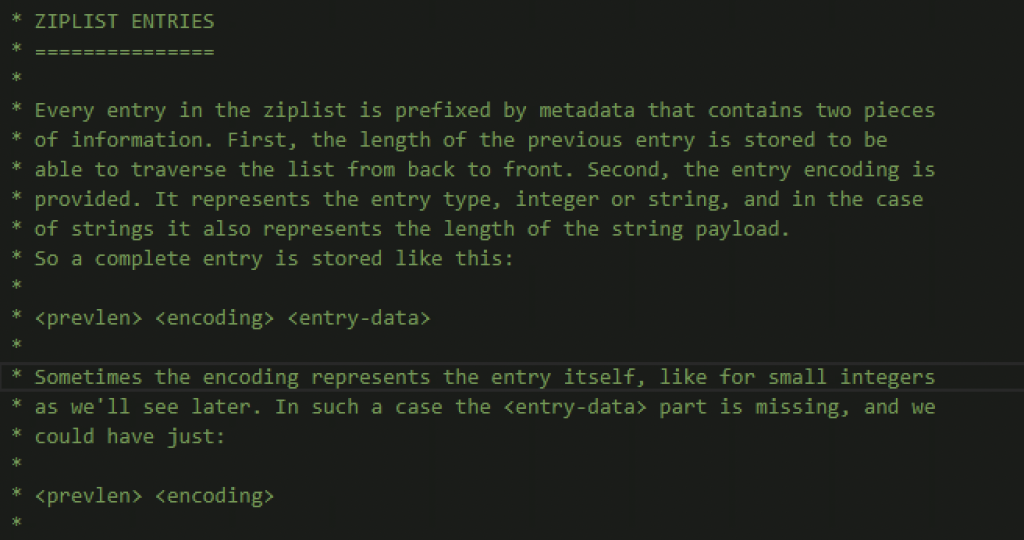
这里介绍了两种entry
(1)prevlen前一个entry的大小,encoding不同值情况下的类型和长度,entry-data存储数据
(2)相比上一种少了entry-data,使用int时,会尝试先将string转为int存储,节省空间
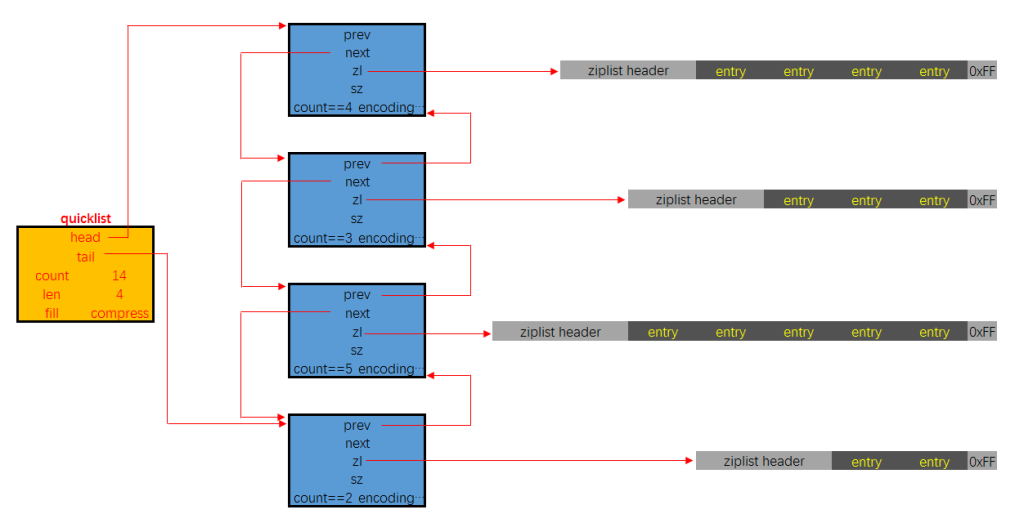
快表,quicklist,是一种双向链表,实际上链表的节点底层还是个ziplist
字典/哈希表,dict,本质就是hash表
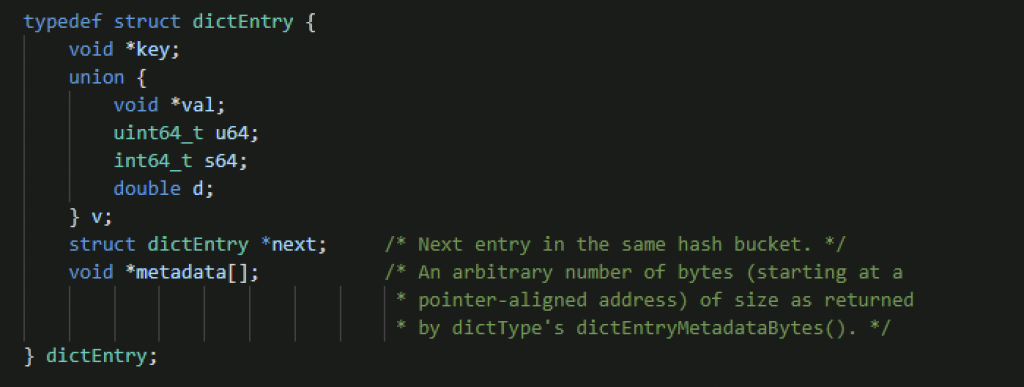
和其他哈希表的问题一样,都存在哈希冲突问题,这里是采用了链地址的方法,通过next指针将多个值连在一起来解决哈希冲突,当保存的键值对过多或者过少的时会通过rehash进行扩展或者收缩
整数集 intSet是集合类型的一种实现,当一个集合只包含整数值元素而且元素量不多时就会使用该类型实现
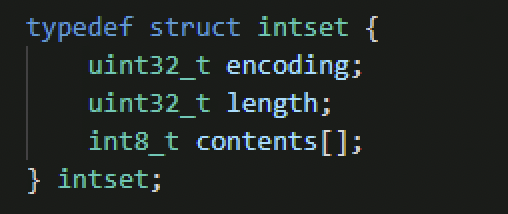
结构比较简单,encoding标识编码方式,length代表存储的个数,content就是一个数组,数组的值按从小到大有序排序且不重复
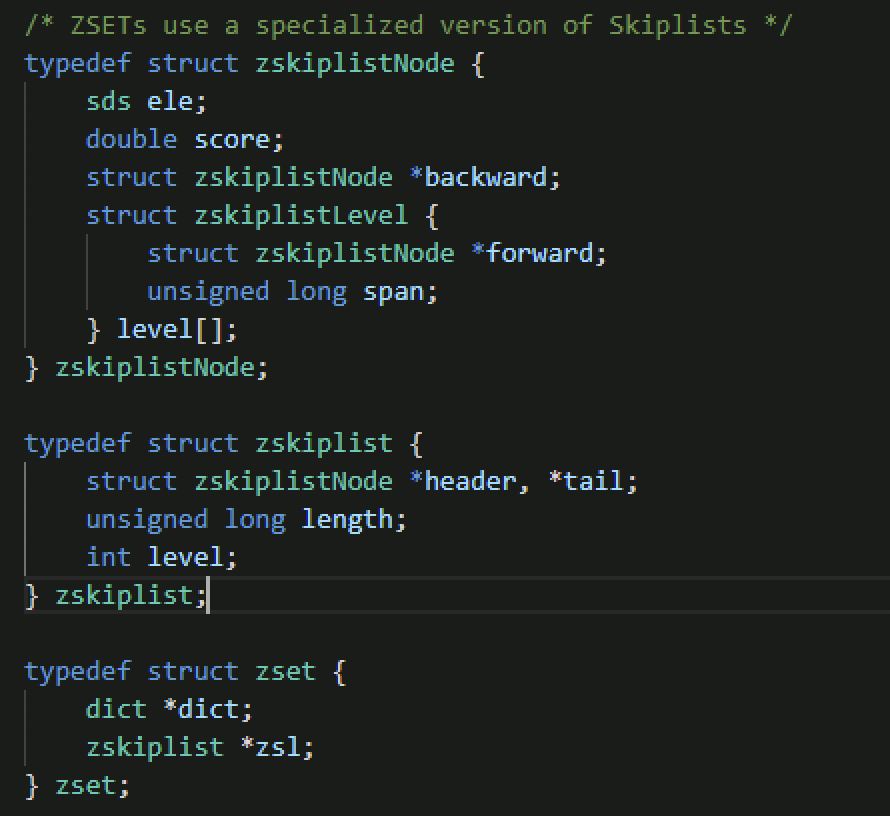
跳表 SZkipList,这是Zset的底层结构,为了保证在查询、删除、添加在对数期间完成,但是存储空间会相对较大,所以属于用空间来换时间的一种结构,跳表定义在server.h中