前言
相信大家都做一个需求,需要在一个map里找到存在或者不存在的数据,通常会把数据库load到内存中,然后再进行判断,但是当数据几十万甚至几百万时,这个内存可吃不消,这种情况下,我们如何在不占用很多内存的情况下很好实现这个需求呢?
1、简单介绍
布隆过滤器(Bloom Filter)是一种数据结构,用于快速检查一个元素是否属于某个集合中。它可以快速判断一个元素是否在一个大型集合中,且判断速度很快且不占用太多内存空间(优势)。
布隆过滤器的主要原理是使用一组哈希函数,将元素映射成一组位数组中的索引位置。当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。
由于哈希函数的映射可能会发生冲突,因此布隆过滤器可能会出现误判,即把不在集合中的元素判断为在集合中。但是,布隆过滤器不会漏判,即不会把在集合中的元素判断为不在集合中。
2、添加数据到布隆过滤器中
布隆过滤器的数据添加过程主要分为以下几个步骤:
创建一个位数组,初始化所有位为0。
设定k个哈希函数。
对要添加的元素进行k次哈希操作,得到k个哈希值。
将位数组中这k个位置的值都设为1。
例如:创建步长为10的位数组,初始化所有为0,设定3个哈希函数,哈希函数1:除10取余,哈希函数2:翻转后除10取余,哈希函数3:每位的ASCII码值相加后除10取余,通过三个哈希函数后会得到相应位置上,假设为3,4,6,那么位数组上的3,4,6上值为1
如下图所示:
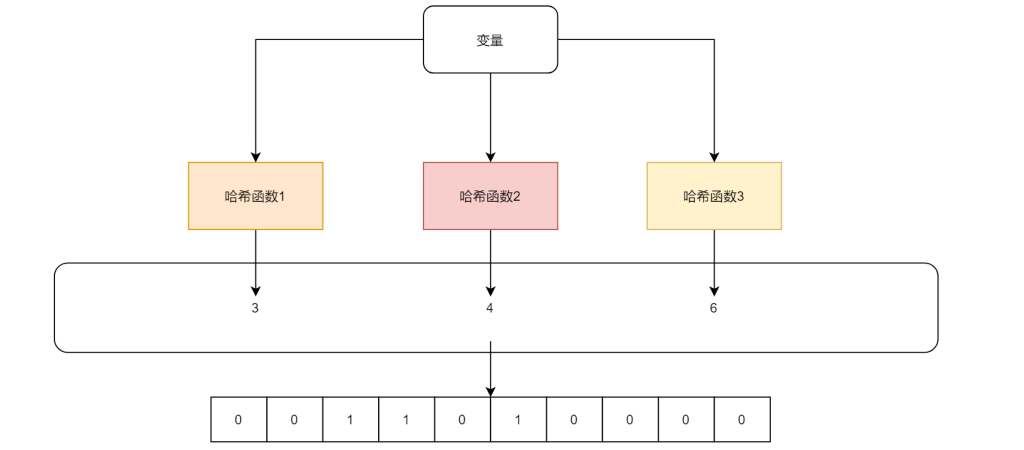
所以最终布隆过滤器不存数据本身,当数据需要判断是否存时只要对数据进行一样的哈希处理去对比相应位置上是否有1即可,若相同则这个数据可能存在,因为会有哈希碰撞,这里也就是我们所谓的误判的情况
3、优缺点
优点:
(1)时间和空间效率高:布隆过滤器的时间复杂度和空间复杂度都是O(k),其中k为哈希函数的数量。因此,它可以在较小的空间内快速判断某个元素是否在集合中。
(2)误判率低:布隆过滤器虽然可能出现误判,但是误判率可以通过调整哈希函数数量和位数组大小来控制,可以根据实际需求进行调整。
(3)支持高并发:布隆过滤器支持并发查询和添加数据,可以在多线程环境下使用。
(4)易于实现:布隆过滤器的实现比较简单,只需要实现几个哈希函数和一个位数组即可。
缺点:
(1)无法删除已添加的数据:由于布隆过滤器的哈希函数不具有逆向性,所以无法删除已添加的数据。
(2)误判率无法避免:由于布隆过滤器的设计原理,误判率无法避免。当哈希函数的数量不足或位数组的大小不够时,误判率可能会很高。
(3)无法精确判断元素是否存在:由于布隆过滤器的设计原理,无法精确判断某个元素是否在集合中,只能判断它可能存在或一定不存在。
结论:
综上,布隆过滤器虽然很高效,但是会有误判的问题,所以在实际场景中需要判断数据的体积去容忍的误判率去设计哈希函数和步长,对应的哈希函数是有成本的,越复杂消耗的资源肯定越多,所以在使用时要权衡,同时由于哈希函数的特性,是很难无法对插入的数据进行修改,因此需要考量到这个点(业界有更新的一种实现叫布谷鸟过滤器,可以实现修改)
4、实现
使用google的guava中的BloomFilter可以快速创建一个布隆过滤器
/**
* 创建布隆过滤器
*
* @param expectedInsertions 预估插入总数
* @param falseProbability 误判率
* @return {@link BloomFilter}
*/
public static BloomFilter<String> create(int expectedInsertions, double falseProbability) {
return BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), expectedInsertions, falseProbability);
}
/**
* 布隆过滤器中判断是否存在
* <p>
* 若布隆过滤器中存在碰撞的数据可能会误判,但若数据不存在则必然不存在
* 兼容出错时默认返回true
* </p>
* @param bloomFilter 过滤器
* @param t t
* @param <T> t
* @return {@link Boolean}
*/
public static <T> Boolean isContains(BloomFilter<T> bloomFilter, T t) {
try {
//可能初始化不成功 作为一个兼容判断
if (null == bloomFilter) {
return Boolean.TRUE;
}
return bloomFilter.mightContain(t);
} catch (Exception e) {
logger.error("布隆过滤器判断失败: {}", e.getMessage(), e);
}
return Boolean.TRUE;
}另由于使用bloomFilter是在某个服务中使用的,在分布式多点的环境下怎么办呢?
首先redis其实支持集群的bloomFilter,但是因为使用redis本身的话需要使用pro才能使用redis的集群版,不然布隆过滤器存在redis单点中还是有单点故障的隐患,于是取巧配合google的guava的local cache设计一个二级缓存
但是该实现仅适合延时有较大的容忍度的情况,同时还需要考虑bloomFilter的刷新时机
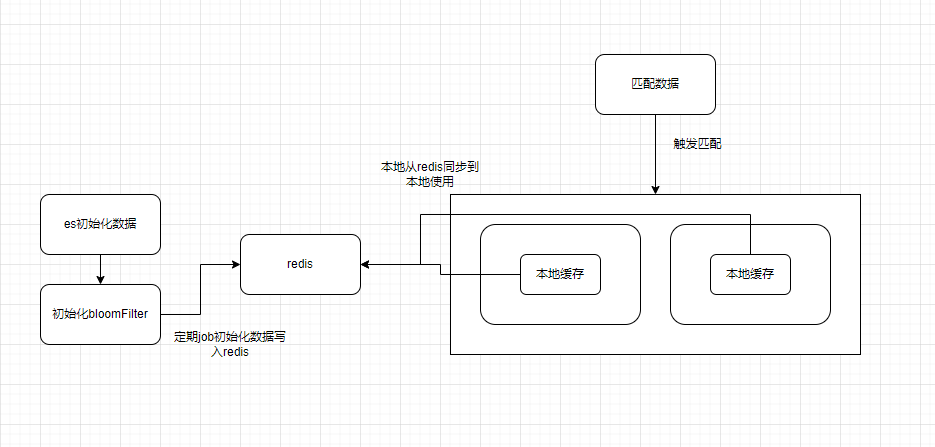
流程:
1、数据由某个节点定时刷新,并更新到redis中
2、其他节点使用本地缓存,从本地加载布隆过滤器,但是首次会从redis中取出并存到内存中,目的其一是减少对redis的读取,毕竟是一个比较大的value对象,其二是可以做到不同的点延时共享所有的布隆过滤器
3、本地缓存设置过期时间,定时刷新本地缓存中布隆过滤器,本地缓存是支持并发读写的,同时控制更新的频率,目的也是为了减少从redis中读取数据