SQL想必大家都不会陌生,在大数据开发和引用中,使用SQL是非常常用,而Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合ANSI标准 SQL 语义的开发语言,它面向用户的 API 层,不同于JAVA、SCALA去开发业务逻辑,虽然灵活,但有一些不足,并且Flink 底层 Runtime 本身就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一
虽然跟传统的MySQL方言很相似,但是意义并完全一样,在学习之前,我们需要准备好环境,可以使用docker run一个flink,或者直接在本机运行(我使用的是MAC)
进入flink/bin/
我们可以看到里面有很多.sh
其实不难发现,每个.sh文件命名都表明了运行的方式,之前有介绍过Flink的运行环境,此处我们使用到的是Flink SQL,所以直接打开./sql-cluster.sh

其实严格意义上来说,sql-client还只是一个“玩具”,看到上面写着BETA,我们生产环境中一般都不会用这种方式运行,像ververica platform都有提供封装好的SQL编辑器,后续我分享一下Streamx的使用,此处我们主要是熟悉Flink SQL
运行起来以后,就可以放一下,我们先学习一下语法
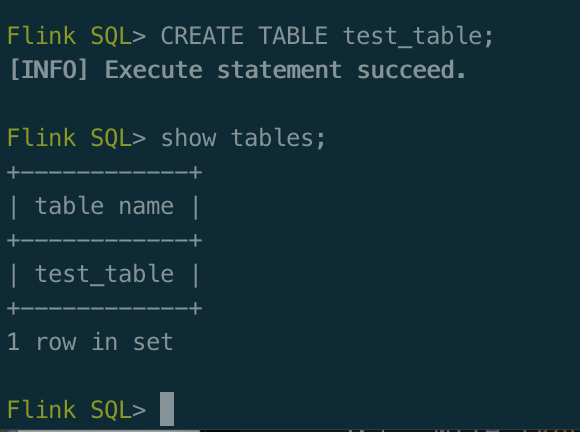
CREATE TABLE 建表,语句用于向当前或指定的 Catalog 中注册表、视图或函数。注册后的表、视图和函数可以在 SQL 查询中使用
SELECT 查询数据
SHOW 用于列出所有的catalog、database、function等
INSERT INTO|OVERWRITE 用来向表中添加行(INTO是追加,OVERWRITE是覆盖)
是不是和我们学习MySQL的差不多,CREATE TABLE建表,SHOW查看建表的结果,INSERT INTO插入数据,SELECT查询出数据,这些都是我们最基本和最简单的SQL语法
其他语法后续介绍,先思考一下,如何使用Flink SQL,因为是流式计算引擎,所以我们需要source和sink,使用Flink SQL是通过INSERT sink数据到下游,那么source,我们一般会有kafka,将业务层的数据采集到kafka中,我们看一个例子
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP(3)
-- 定义数据的来源
) WITH (
-- Using the kafka connector
'connector.type' = 'kafka',
-- kafka topic
'connector.topic' = 'user_behavior',
'connector.properties.bootstrap.servers'='服务地址',
-- Read from start offset
'connector.startup-mode' = 'earliest-offset',
-- The data source format is json
'format.type' = 'json'
);
CREATE TABLE sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://mysql:3306/test', -- jdbc url
'connector.table' = 'test_table',
'connector.username' = 'username',
'connector.password' = 'password',
-- Default 5000, changed to 100 for demonstration
'connector.write.flush.max-rows' = '100'
);
INSERT INTO sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm');此时如果打开localhost:8080的web ui界面就能看到跟我们使用datastream api实现一样的效果,但是我们不需要繁琐的引包、建项目和编写JAVA/SCALA代码就能实现一个简单的ETL
下面介绍一下CDC,刚刚的例子我们使用到了kafka,当前的场景,假设是从mysql中提取数据到elasticsearch,需要什么呢?我们需要一个从mysql获取数据到kafka的工具或者平台,业界比较成熟的方案:debezium、canal、streamsets等等,我介绍一个基于debezium实现的flink cdc:https://github.com/ververica/flink-cdc-connectors
这是一个非常优秀的框架,同时解决了我们需要维护多套组件的问题
CDC意思是捕获数据的变化,底层使用到的debezium其实最早也是跟kafka对接,我们再从kafka中拿到数据,但是这个框架很好贴合了flink的原生,一站式解决ETL方案,具体的介绍可以去github看,我们来使用一下
将官方的包下载放入flink的lib目录下即可,结合打开sql-client.sh
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP(3)
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'username',
'password' = 'password',
'database-name' = 'database',
'table-name' = 'user_log'
);
CREATE TABLE sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://mysql:3306/test', -- jdbc url
'connector.table' = 'test_table',
'connector.username' = 'username',
'connector.password' = 'password',
-- Default 5000, changed to 100 for demonstration
'connector.write.flush.max-rows' = '100'
);
INSERT INTO sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm');我们可以发现,除了with其他基本一样,如果我们需要把sink改成elasticsearch,同样的,修改一下with即可
CREATE TABLE es_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'pvuv'
);总结:
使用Flink SQL能大大降低我们的学习成本,提高开发效率,目前还有一些不足和不兼容的地方,社区也在慢慢完善,相信在将来能给我们展现更好的Flink SQL,虽然是不支持一些特性和API,但是我们可以做取舍,将但部分的业务转为Flink SQL,像字节跳动,基本上90%的业务都适用Flink SQL实现,可见其重要性,其他进阶和高级的使用后续我们再结合例子来介绍。