一、背景
- 背景:描述此文档的背景和要解决的技术问题
在微服务治理下的应用系统之间形成天然的数据孤岛,项目与项目之间往往会需要某些数据,以目前的方案实现起来相当困难,并且已有的设计方案很难做到高可用(数据一致性问题、业务耦合度过高,性能也不高)
为此我们需要能够集中管理并且能够低延时的同步和查询数据的中间服务
- 技术应用场景:
跨项目之间的数据读取和使用
跨项目数据同步
数据汇总
对账中心、实时报表和OLAP
- 整体思路:简要描述技术应用的整体思路和逻辑
(1)采用ETL的方式对数据源进行采集并下沉,微服务之间的调用和同步进行集中式处理
(2)对下沉的数据进行结构化处理,进行同源异构处理,为构建数据仓库、数据湖做基础和准备
(3)构建面向数据治理的平台
二、方案介绍
2.1 前世今生
canal
基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
缺点:
(1)运维成本较高,虽然后续版本有升级一些admin web的增强组件,但是并没有很大程度降低运维成本
(2)服务资源管理被动,没有类似于Resourcemanager、kubernetes这样的资源调度管理器维护这些服务,很容出现down的情况
(3)伴随难以避免的业务变动,整体调整代码、迭代、上线等变得寸步难行
streamsets
大数据实时采集和ETL工具,可以实现不写一行代码完成数据的采集和流转
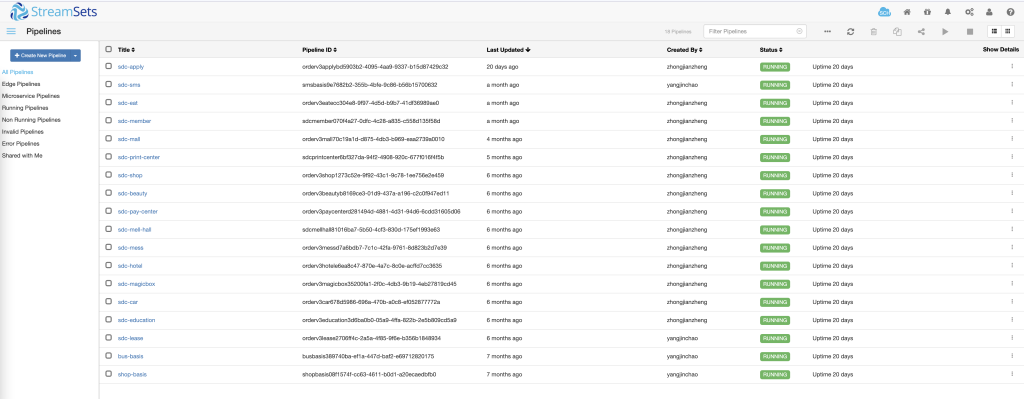
缺点:
(1)无法搭建集群服务,并且只有社区版免费使用,需要监控和管理等需要购买企业版
(2)版本升级后虽然功能丰富了,支持更多的组件,但是可以明显看到它引导你走向他的云端服务化的付费功能,可能会很爽但是要钱
(3)因为是端到端的中间ETL采集系统,所以它对于数据层面而言,它最多实现了At Lease Once的语义,虽然有故障恢复,但是因为不是集群,大量mysql binlog采集瓶颈肉眼可见的很明显
(4)出现run error的情况,无法自行恢复,会处于假死的状态,下游系统无法感知这种问题,也是比较严重的情况,一般如:网络问题、大量数据被内存资源限制了等等,都会出现这种情况,暂时无法解决,只能手动重启
(5)文档资料并不是特别齐全
2.2 概念补充
- 投递语义
一个sender发送一条message到receiver,根据receiver出现fail时sender如何处理fail,可以将message delivery分为三种语义
(1)At Most once: 对于一条message,receiver最多收到一次(0次或1次).
可以达成At Most Once的策略:
sender把message发送给receiver.无论receiver是否收到message,sender都不再重发message.
(2)At Least once: 对于一条message,receiver最少收到一次(1次及以上).
可以达成At Least Once的策略:
sender把message发送给receiver.当receiver在规定时间内没有回复ACK或回复了error信息,那么sender重发这条message给receiver,直到sender收到receiver的ACK.
(3)Exactly once: 对于一条message,receiver确保只收到一次
持续地对整个系统做snapshot,然后把global state(根据config文件设定)储存到master node或HDFS.当系统出现failure,Flink会停止数据处理,然后把系统恢复到最近的一次checkpoint。其中分为幂等型和事务型,有不同的场景和实现难度
- CDC
全称Change Data Caputre,一种用于捕获数据库中数据变更的技术
包括:
(1)数据分发:将一个数据源分发给多个下游,常用于业务解耦、微服务
(2)数据集成:将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析
(3)数据迁移:常用于数据库备份、容灾等
2.3 Flink CDC
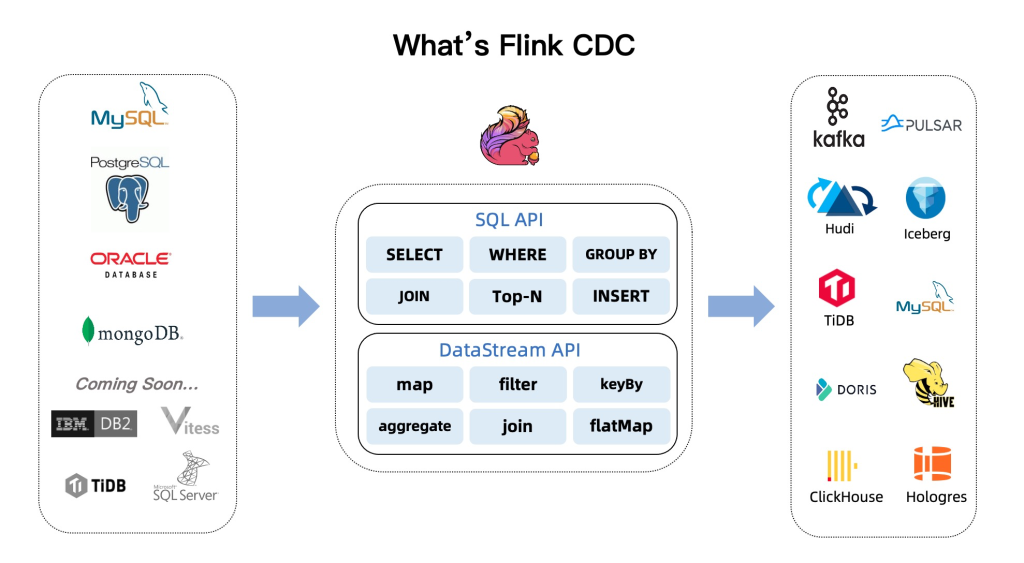

Flink CDC 的核心特性可以分成四个部分:
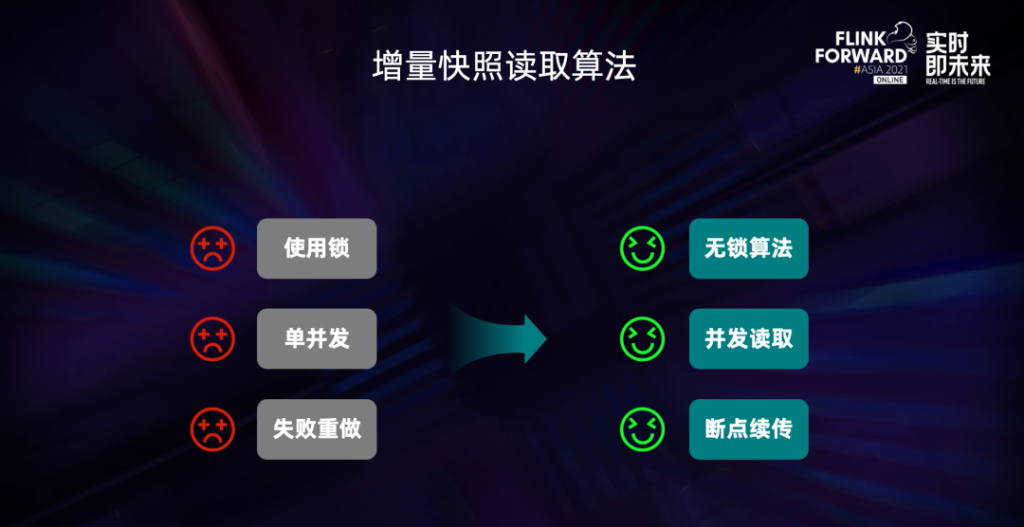
- 一是通过增量快照读取算法,实现了无锁读取,并发读取,断点续传等功能。(底层使用了debezium,旧版是需要全局锁的)
- 二是设计上对入湖友好,提升了 CDC 数据入湖的稳定性。
- 三是支持异构数据源的融合,能方便地做 Streaming ETL的加工。
- 四是支持分库分表合并入湖。接下来我们会分别介绍下这几个特性。
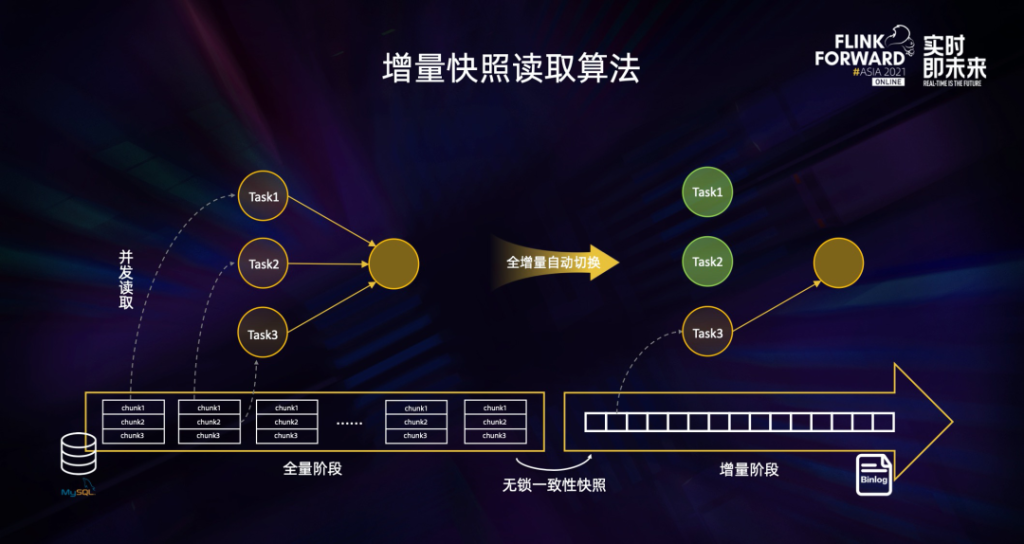
增量快照读取算法的核心思路就是在全量读取阶段把表分成一个个 chunk 进行并发读取,在进入增量阶段后只需要一个 task 进行单并发读取 binlog 日志,在全量和增量自动切换时,通过无锁算法保障一致性。这种设计在提高读取效率的同时,进一步节约了资源。实现了全增量一体化的数据同步
缺点:
(1)目前table api只支持一对一的采集,不支持分库分表的多源采集,datastream api可以多表,但是不能使用checkpoint(作者下一版将推出CDAS 和 CTAS 的数据同步语法可以完美解决这个问题)
(2)提交Flink-sql的方式在维护角度上很鸡肋,需要使用sql.client,在cmd界面提交(引入zeppelin解决)
(3)需要一套Flink运行的流式引擎架构和较大的服务器资源
(4)学习成本(为了降低学习成本,借鉴大厂的推行的sql的方案,采用Flink-sql提交作业可以很大程度降低学习成本,由于Flink 的 SQL 完全遵循 ANSI SQL 标准,熟悉Mysql、SqlServer都不会觉得陌生,但凡会CRUD都不止于混不上饭吃)